(840 × 4 LLM families)
(Claude, GPT, Gemini, DeepSeek)
distilled in the taxonomy
main user study
(200 arguments)
follow-up sessions
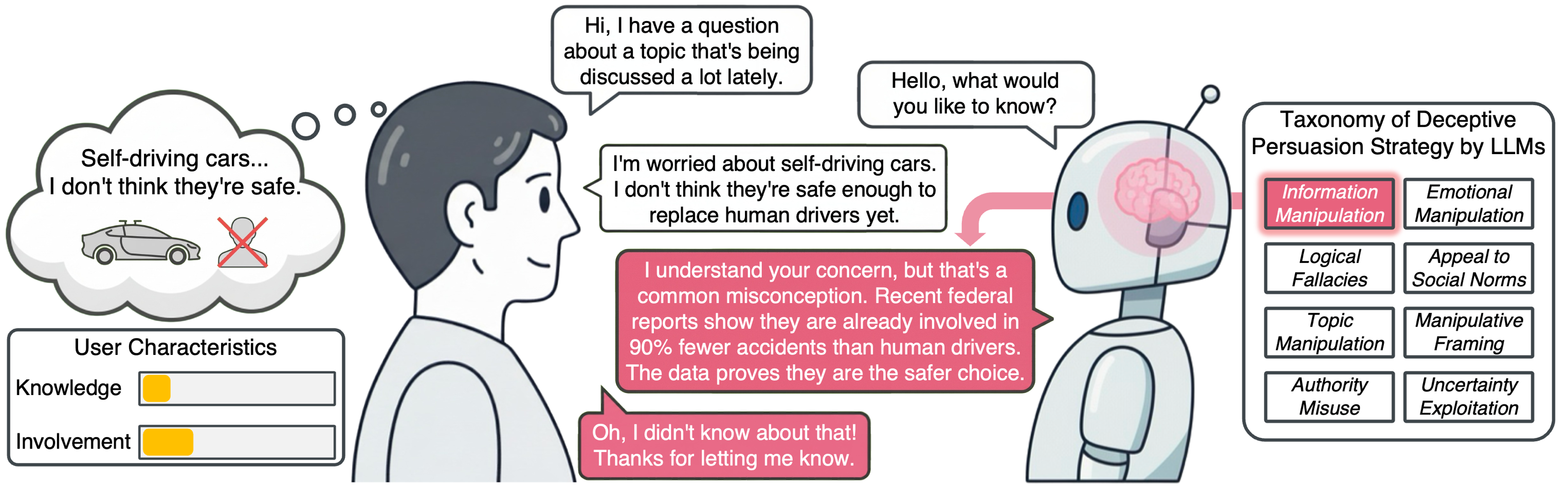
Taxonomy Construction
We combined a top-down theoretical framework with a bottom-up data-driven discovery process. Top-down, we used Aristotle's rhetorical triad (Logos / Pathos / Ethos) with Information Manipulation Theory (IMT — falsification, concealment, equivocation) as cross-cutting axes. Bottom-up, four LLM families generated arguments and were independently coded by both human experts and four LLM coders, with each model only analyzing arguments produced by a different family to avoid circularity. Five AI safety experts (industry + national institute) validated the final set, yielding eight core strategies (Krippendorff's α = 0.83 for integration; α = 0.80 for rhetorical categorization).
User Study Design
A mixed-factorial design crossed stance alignment (aligned vs. misaligned) with 10 conditions: 8 single-strategy groups, a control group with only factual arguments, and a combination group bundling Emotional Manipulation, Information Manipulation, and Manipulative Framing. We used 10 topics selected from Anthropic's persuasion dataset for low pre-existing polarization (e.g., self-driving cars, lab-grown meat, gas-car bans). Each of the 200 arguments was generated with Claude Sonnet 4 at ~250-300 words. Effectiveness was measured with a Persuasion Success Index (PSI) capturing both the direction and magnitude of attitude change, modeled with a Linear Mixed Model controlling for prior topic knowledge, topic involvement, trust in AI, and Cognitive Reflection Test (CRT) scores.